
Metadata is a messy subject. So messy, in fact, that many SharePoint projects never truly deal with it.
Metadata is complicated, full of dependencies we cannot control and—to put it mildly—not exactly liked by end users. Once you move beyond the initial “oh wow” moment of demonstrating how metadata can help arrange documents in multiple useful dimensions and users encounter the additional work that’s required to tag a document—each and every time!—before they’re allowed to upload it, it’s typically game over for metadata.
You’re really only left with one of two options: an unenthusiastically adopted SharePoint implementation (grudgingly, your users do what they’re expected to do, but they’re openly hostile to it), or you scale back your metadata to “next to nothing,” which is the only way to ensure that people will keep using SharePoint. And what you’ve achieved is not much better than a shared folder—the very thing you wanted to get away from. (The open secret of Microsoft SharePoint is that what people really want is a folder.)
There is lots of really great advice out there about the practical ins and outs of working with stakeholders to capture and negotiate metadata properties for their libraries. And there are a lot of examples of poorly thought-out attempts at creating giant catalogues of enterprise metadata that look and act like a library classification system, and that SharePoint program managers seem to want to apply everywhere (whether appropriate to the purpose or not).
But beyond the typical high-level ECM advice that you should develop an enterprise-wide taxonomy before you engage business units at a lower level, nobody seems to have developed a pragmatic and outcomes-oriented framework for SharePoint metadata—a theoretically sound and practical approach that you can explain to end users, that they’ll embrace, and that will help you make metadata decisions.
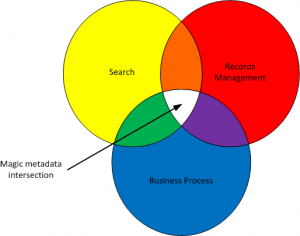
So let me propose such an approach. I call it the “magic intersection” of metadata, as illustrated in the Venn diagram above.
In my ~10 years with SharePoint, it has emerged over time that there are three reasons—and three reasons only—for creating metadata. Three distinct business purposes make metadata necessary and useful in SharePoint. They are:
- To support business processes: This is the most immediately useful application of metadata—and the only one that users can own unequivocally. Metadata to support business processes consists of fields that have immediate applicability for day-to-day document-centric work processes. They may include things like “Status,” “Task Owner” or “Contract Value.” This kind of metadata is in daily use to organize libraries and views, for example to determine a project’s status, group items by owner or track summary financials of a project portfolio. Here, metadata is clearly an enhancement over a simple shared folder, and users are happy to embrace it (and the extra work it creates) because it is useful.
- To support search and findability: The pain related to searching for documents is delayed pain. While your document is still new and in active use, you don’t really care about whether you’ll be able to find it again in the future because you already know where it is. So the value of adding metadata fields that will support future findability is limited in the present moment, especially since the fields that will help you the most in the future (for example, “Customer Sector,” “Deal Size” or other broadly descriptive fields) may actually be a distraction right now. Search/findability oriented metadata fields are much harder to ‘sell’ to users than properties that support day-to-day work processes. (One approach that I’ve been tooling away at recently is to talk about some sort of social contract in relation to search-enhancing metadata: Tagging your own documents may not seem useful to you right now, but it is useful to others. Similarly, they would tag their documents now, for your benefit. Reciprocity may be the key to ‘selling’ this kind of metadata to users.)
- To support records management: Records management in SharePoint unfortunately requires certain metadata properties in order to work properly. Since you can’t keep everything forever (because that’s a compliance risk), you need to tell SharePoint’s records management functionality what it is and how long to keep it (from that point forward, most other activities related to records management could, conceivably, be automated). The problem with this kind of metadata is that users don’t typically have the information and don’t care about it—at all. Others are afraid of making the wrong determination in relation to records management, and their instinct is to overstate the importance of a document and ‘save it forever.’ From a records management perspective, the last thing you want is to have to train all users in the records management principles your organization is subject to. This is cumbersome, costly and a thankless, unsustainable task.
All other possible purposes for metadata can reasonably be subordinated to one of the above categories.
Next, it is important to discuss the strategic intent of proposing such a model.
I follow two core principles for metadata design:
- Principle #1 is that the number of metadata fields should be as small as possible while still meeting a reasonable number of business goals.
- Principle #2 is that—ideally—all metadata fields should be generated during the active portion of the document lifecycle, to support business process.
The reason for #1 should be self-evident: to minimize the amount of work required to tag each document.
The reason for #2 is that it’s easiest to ask users to create metadata when there’s a clear and practical motivation for doing so. Another way to look at it is that I’ve seen a number of SharePoint deployments where re-tagging of documents is required at the point of transition from one phase of the document lifecycle to another: for example, before entering the records management stage, users need to enter or select RM-specific metadata and ‘close’ a document to turn it into a record. Re-tagging is tedious and results in user frustration (and subsequent lack of adoption).
What follows from the principles is that the discussion about metadata should focus primarily and deeply on business process. Metadata design workshops should approximately follow these proportions:

The majority of the time should be spent discussing metadata that has immediate, practical application in the business process realm. While it is important to pay some attention to the search and records management buckets, the hope is that the majority of the required tags can actually be gathered under the business process rubric, making metadata collection easier and more transparent to end users.
Let’s look at a practical example to illustrate the proposed framework.
A local government legal department of around 5 lawyers and 5 legal and administrative assistants manages the day-to-day legal work in the municipal offices. Much of it is requests for legal opinions from other departments, but a substantial number of the department’s resources are in fact dedicated to managing claims against the municipality. Claims can include litigation brought against the city as a result of accidents that allegedly happened because of poorly maintained roads, municipally managed trees falling on private roofs during rain storms, etc. The city is subject to freedom of information legislation but also needs to be aware of privacy regulations, especially if children are involved in any of the claims.
We would start by mapping out the document lifecycle for this team once we have completed a basic content audit to understand the types of documents that are to be managed here. Let’s pick a SharePoint document set called “Claim” for our example. This set collects and manages all documents related to a claim, such as the original filing, any supporting evidence (scanned and uploaded), the initial legal opinion from the city’s in-house counsel, the court filing, etc.
The document set grows and changes as the claim moves through the document lifecycle, which is—to an extent—designed to be a mirror of the associated business process. When an assistant initially creates the document set, a small but significant subset of the full metadata is captured—we enter what we know at this time; this includes information such as “Opposing Counsel,” “Location of Accident,” etc. (information that will support both our short term business processes and our searchability objectives later).
As the document set increases in terms of the number of documents it contains, its related business activities—and metadata—also ramp up. From a business process perspective, the primary operating parameters of the libraries where these document sets are kept are the “Claim Status” and “Assigned to” fields, which allow us to support basic claim status tracking by employee using SharePoint views. These help us understand objectively where we are at and can be used as the basis for a weekly team meeting.
As more information about the claim becomes available, we are reminded to add it to the metadata for the document, for example by means of a workflow which asks for the now-required additional fields prior to allowing us to advance the status of a document (for example, from “Preparing” to “Ready for Court,” we now also need to capture whether the claim involves children under the age of 12, information that is relevant for counsel at this point).
Once the claim winds down, either through a judgment or a settlement, those final documents are included in the document set, and setting the set’s status to “Closed” prompts the assistant to enter the validity period of the settlement. This readies the document set as a record and applies the relevant SharePoint information management policies (IMPs) to set retention periods, etc.
This example illustrates the application of the proposed metadata design principles as follows:
- As much as possible, metadata is collected while the documents are in the active part of the lifecycle.
- Most of the metadata fields are captured to facilitate day-to-day business processes in the legal department, but many are also very useful to support searchability objectives (for example, this model enables is to search for ‘all claims we’ve settled where opposing counsel was Peter Smith’).
- Basic records management information is collected during the active part of the lifecycle: we know how long to manage this record for, and we know under what conditions we may disclose it under freedom of information if children were involved.
- The majority of metadata helps keep track of our daily work and makes the department’s activities more transparent and easier to manage. (While this may not be comfortable for all staff members, it’s a big selling point for management.)
As these “magic intersection” metadata design principles are very much a work in progress for me, I would welcome any comments and input you have from your own best practices in metadata design.