
Update February 2020: Since writing this blog post, I have updated the method described below to using a newer, more broadly compatible approach which works with all/most versions of Microsoft Office — and also on the Mac and Linux computers. Please refer to this blog post for the updated method.

Across the social sciences, including business ethnography, the so-called “best practice” for qualitative data analysis is to use coding, the process of categorizing data by applying tags to portions of it. These tags, and the data they label, can then be used to underpin analysis and interpretation. This technique allows researchers to develop category sets—arranged, perhaps, into different themes—which span different qualitative data. For example, one might conduct several interviews, transcribe them, and then code them to examine what themes emerge from the whole set of interviews. Textual material in its original form may be unwieldy and, as a result, somewhat difficult to work with (“…where did I see that quote again…?”). Coding increases contextual data retrieval, speeds up the analysis phase of a project, and enables easy comparisons across large data sets.
Coding in qualitative data analysis also has its “dirty secrets.” For one thing, it is widely discussed but not nearly as universally practiced. This is because it is hard, focused work and therefore costly in terms of time (which, in the context of business ethnography, translates to money). Coding also risks creating the impression, particularly in the hands of less experienced practitioners, that it somehow enables insights that are “statistically” valid because they have been mined from the entire data set using a rigorous process. While it may occasionally be handy for political reasons to be able to make claims about the “statistical validity” of one’s research, coding cannot and will not somehow magically convert an ethnographic dataset into quantitative research.
Coding’s other dirty secret is how expensive the specialized software is that is used in the process. There is only a handful of vendors that compete in this market segment, which is small and mostly populated with users who demand a lot but want to pay as little as possible (students, academics). The most common specialized QDA software suites are Atlas.ti, MAXQDA, and NVivo. These are software packages that need to be installed on a researcher’s computer (PC or Mac). The three main contenders are in a features “arms race” with each other, regularly introducing new capabilities that fewer and fewer users actually need. There are also many other, minor players. I would categorize these broadly into (1) “barely maintained,” older style Windows software (some of it even available for free or as open source software), (2) adjacent or look-alike applications that on closer inspection don’t really offer the same thing, and (3) web-based applications. There are two main web-based apps: Dedoose and Saturate. Neither strikes me as particularly trustworthy or reliable; in fact, Dedoose has a documented history of losing users’ projects.
But back to pricing: part of the three main vendors’ arms race strategy is to ensure that the market is kept at a high price point, especially for private sector researchers. While their software is often deeply discounted for academic use (and may sometimes even be available for free via one’s university), the “commercial” pricing policy seems to be something like this: since private sector researchers make money from doing qualitative research, they should pay as much as possible for the required tools. At the time of writing, NVivo would cost me $1,380 (US), MAXQDA is €990, and Atlas.ti is $2,037.12 (Canadian; I presume this is at today’s exchange rate).
Finding a cheap & cheerful QDA coding solution
A recent client project involved a relatively small data set (10 interviews of 20-30 pages each) and what ended up being a fairly small codebook (~30 terms). However, while I had conducted the interviews, I was collaborating with another researcher who was going to do the coding work. We were going to write collaboratively, so both of us needed simultaneous access to the coded data.
In this situation, we would have needed two copies of one of the standard QDA packages, at full price. Neither my client nor I was going to pay for that. I had an older copy of MAXQDA kicking around, so I investigated upgrading it, but the price point remained impractical. Most importantly, our needs were actually quite simple: manual coding for somewhere between 200 and 300 pages of transcripts, an ability to easily extract and consolidate all tagged excerpts, using—ideally—a readily available toolset that requires little to no ramp-up time. Enter Microsoft Word, Excel and Visual Basic for Applications (VBA), Microsoft’s automation scripting language for Office.
At the beginning of this journey, it occurred to me that Word’s commenting feature—part of the “Review” section in the ribbon—would be a simple and effective way for anyone to code text-based data. I began to google for a solution and happened upon this thread at “Mr. Excel,” a forum for Microsoft Excel users. The thread itself is quite old, but—if you follow it all the way through—offers a number of iterations of a VBA script that extracts Word comments, together with the tagged text itself, into an Excel spreadsheet. The discussants are iterating through different versions of Office (it appears that Microsoft occasionally evolves VBA syntax and capabilities) and through different versions of the requirements (someone needs it to do this, another person needs it to do that). I started to test various versions of the script as I read, noticing what worked and what didn’t, and learning a little about VBA in the process. Upgrades to newer versions of Office seemed to invalidate most of the earlier scripts, and I began to doubt that this investigation would prove viable, but user MaxMW from Sweden eventually posted a final updated version that works in the current version of Word.
I should clearly state some disclaimers and other things you should know before going any further.
First, I didn’t write this code. I merely changed it a little.
Second, it works in Microsoft Office 2016 for Windows (I have the current/latest build in February 2018), and I don’t know if it works in earlier versions.
It does not currently work in Office for the Mac. I believe this is because VBA for the Mac uses different code to open files. I haven’t had the time to explore this further. Perhaps someone else can figure it out, and I’d be delighted to post the Mac code here, too.
Finally, I make no warranties about this whatsoever, nor am I going to be offering support. You’ll have to figure out how to ultimately make it work for yourself. But of course you’re welcome to leave comments and questions below.
Overview
First, I’ll outline the principle of how this works so that you have an overview.
Ingredients:
- Microsoft Word for Windows
- Microsoft Excel for Windows
- One or more Word documents, “coded” using Word comments (see below)
The basic procedure is as follows:
- Prepare a “coded” Word document.
- In Excel, add the VBA macro code (see detailed instructions below) and run it.
- In the file open dialogue, pick the Word document containing the tags.
- After a moment, look for a new Excel worksheet that contains your codes and corresponding data extracts. Save it.
- Repeat for other documents.
Detailed instructions
Update February 2020: Please refer to these new instructions instead of what follows here.
In Word, use comments to code your document. Make sure your comment “labels” are consistent. You can use single or multi-word tags. (However, this solution only works for single layer tags—if you need additional taxonomic layers in your codebook, you’ll have to retrofit them after the extraction process.) Save your coded document.
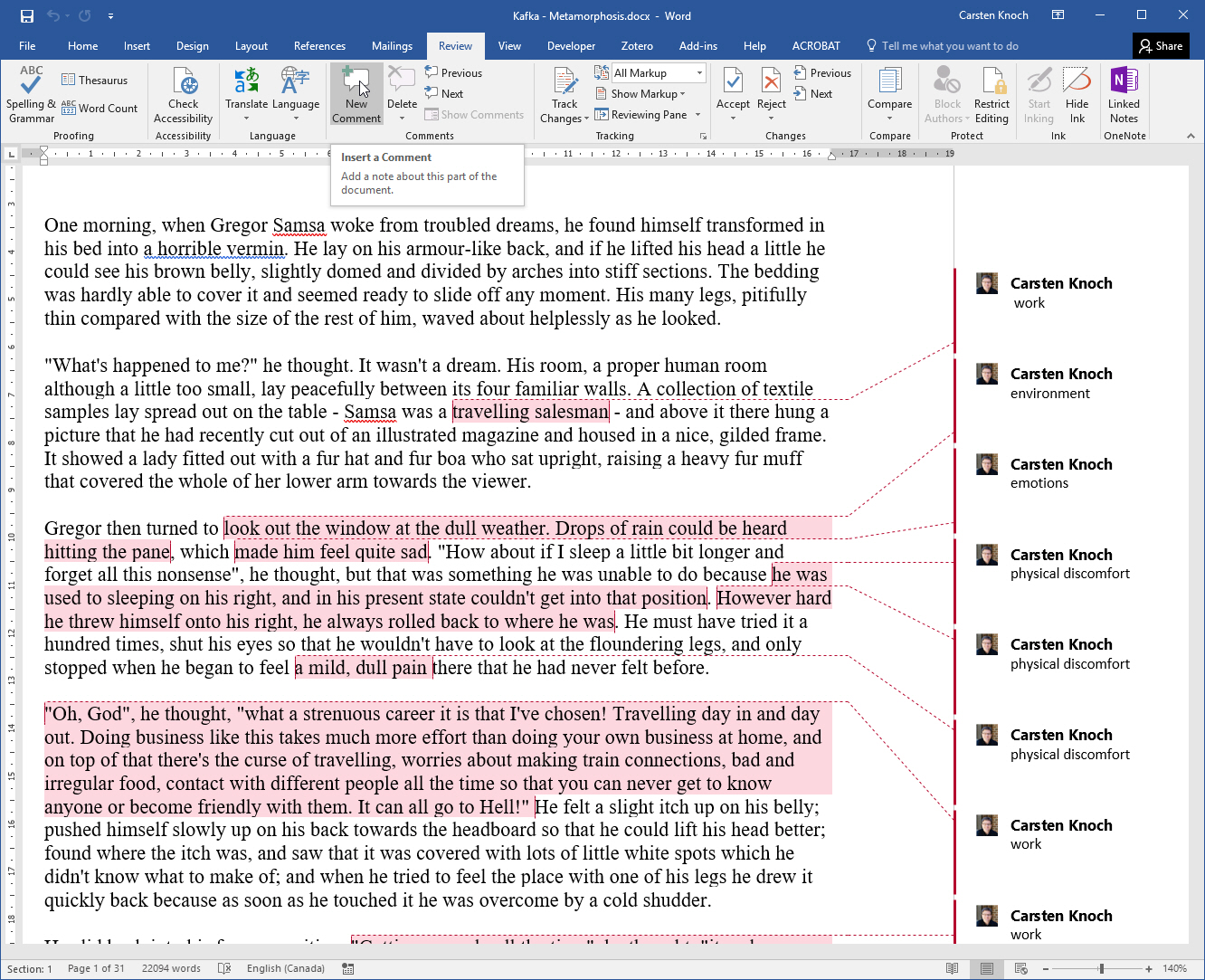
In Excel, you’ll first need to reveal the Developer tab in the ribbon. Do this by going to File (the File tab), Options, Customize Ribbon, and turning it on there.
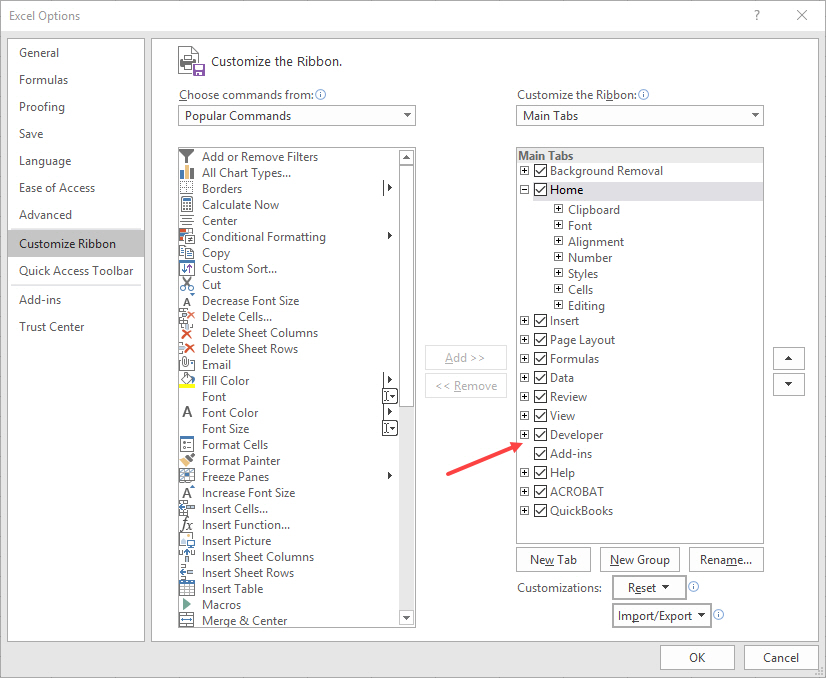
Next, go to the newly activated Developer tab and click on the Macros button:

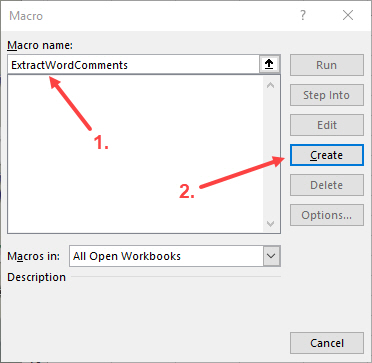
In the resulting dialogue box, (1) give your macro a name (enter: ‘ExtractWordComments’), and (2) click on the Create button:
Next, the Visual Basic for Applications editor window will pop up. The first thing you’ll do is delete the two lines of boilerplate code that are in the editor by default:

Now highlight and copy the macro code below and paste it into the window you just cleared out. Here is the code:
Option Explicit
Public Sub FindWordComments()
'Excel 2016 macro to extract comments and comment content from a Word document
'Requires reference to Microsoft Word v16.0 object library
Dim myWord As Word.Application
Dim myDoc As Word.Document
Dim thisComment As Word.Comment
Dim fDialog As Office.FileDialog
Dim varFile As Variant
Dim destSheet As Worksheet
Dim rowToUse As Integer
Dim colToUse As Long
Set fDialog = Application.FileDialog(msoFileDialogFilePicker)
Set destSheet = ThisWorkbook.Sheets("Sheet1")
colToUse = 1
With fDialog
.AllowMultiSelect = True
.Title = "Import Files"
.Filters.Clear
.Filters.Add "Word Documents", "*.docx"
.Filters.Add "Word Macro Documents", "*.docm"
.Filters.Add "All Files", "*.*"
End With
If fDialog.Show Then
For Each varFile In fDialog.SelectedItems
rowToUse = 2
Set myWord = New Word.Application
Set myDoc = myWord.Documents.Open(varFile)
For Each thisComment In myDoc.Comments
With thisComment
destSheet.Cells(rowToUse, colToUse).Value = .Range.Text
'Put Comment label in cell
destSheet.Cells(rowToUse, colToUse + 1).Value = .Scope.Text
'Put corresponding highlighted text in cell
destSheet.Columns(2).AutoFit
'Switch highlighted text column to autofit the text
End With
rowToUse = rowToUse + 1
Next thisComment
destSheet.Cells(1, colToUse).Value = Left(myDoc.Name, 30)
'Put filename of the Word doc in cell A1
'and truncate to max 30 characters
destSheet.Columns(1).AutoFit
'Set comments column to autofit after inserting the filename
Set myDoc = Nothing
myWord.Quit
colToUse = colToUse + 2
Next varFile
End If
End Sub
Now you’ll need to tell Excel about a library it needs in order to actually run this code. This library contains various procedures for opening and operating on Microsoft Word documents. In the Visual Basic for Applications editor window, open the Tools menu, then go to References. In the resulting dialogue, locate ‘Microsoft Word 16.0 Object Library’ and select it (leave whatever else is already selected as it is). Then click on OK:

This completes setting up the macro in Excel. Now you’ll need to run it. Start the process from inside the Visual Basic editor window. Click on a small green sideways “play” button (triangle):

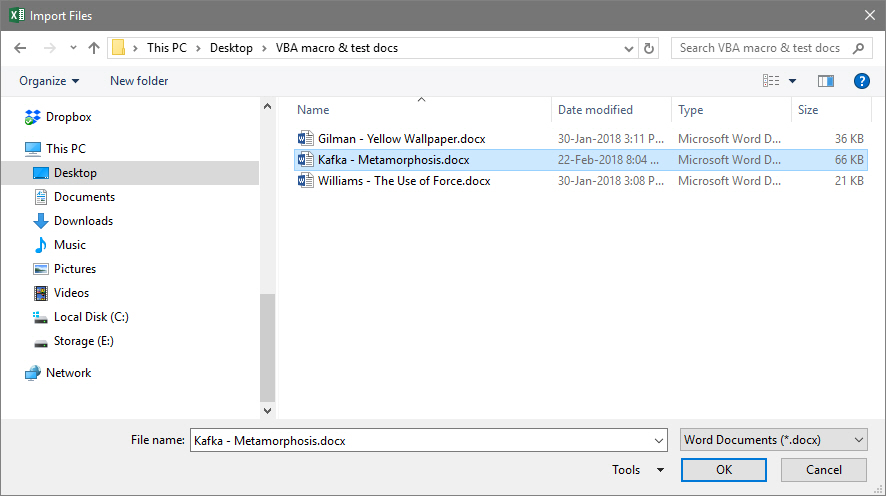
Excel will appear to “think” for a moment and then display a file open dialogue. Find and select one of your Word documents containing comment codes and select OK:
After clicking OK, Excel will seem like it is doing nothing for a moment. How long depends on how many comments/extracts your document contains, but it shouldn’t take longer than 20 or 30 seconds at the most (probably less). Next, go back to Excel itself and find ‘Sheet1,’ which should now contain the extracted codes and corresponding text snippets. It should look like this:

From here, you can add columns manually to add additional metadata that you’ll need for your analysis. For example, if I’m coding interviews, I like to add a column containing the participant’s name. When I later combine all participants’ extracts into a single Excel sheet, I can more easily sort or filter data rows. Generally, the Filter function, in Excel’s Data tab, is very useful for conducting further analysis. First, ensure that your columns have appropriate headers (1), then switch to the Data tab and click on Filter (2), and finally use one or more of the drop-down menus that Excel now shows in your column headers (3) to select tags to show:
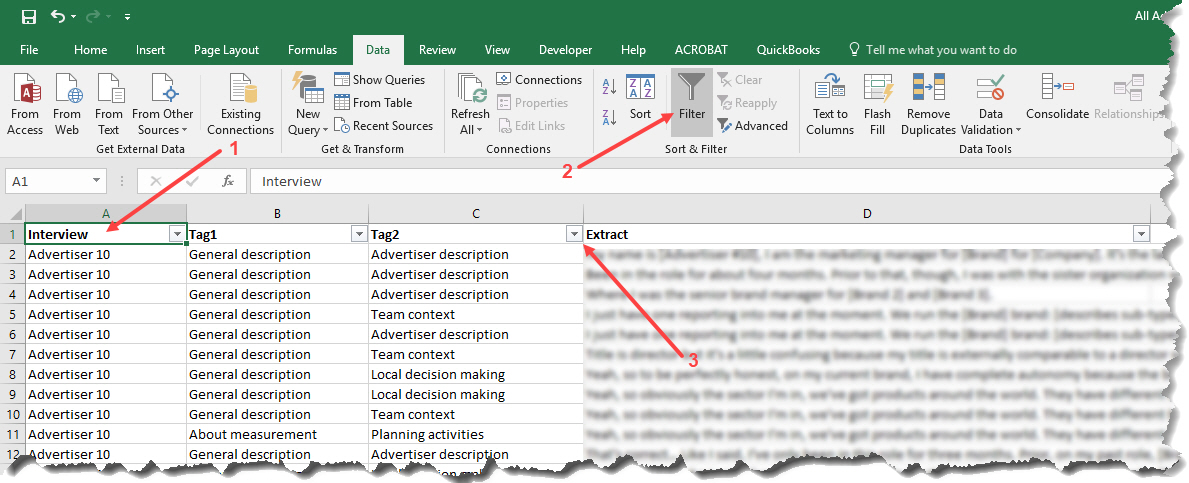
Below is the dialogue shown after selecting the drop-down menu (3). Use it to select one or more tags to query your consolidated database for, and Excel will filter it down to display only the matching rows. Note that you can also use more than one column filter at the same time. This allows you to display certain codes for a subset of interview participants, for example.

Final words & limitations
This method has some obvious drawbacks in comparison to the more advanced QDA tools. Most importantly, it is essentially a one-way process: you can’t easily rename a code and have the change reflected in your coded source documents. As a result, this method is probably not suitable for bigger or longer-term projects, where codebooks continually evolve. You would have to re-run the whole extraction and consolidation process each time you make code changes or updates in your source documents.
Conversely, it has several advantages. The most immediate benefit is that it is extremely low-cost. Furthermore, most computer users can figure out how to use Microsoft Word comments for tagging text-based data. This makes this approach a good candidate for working with cross-disciplinary business teams. You could even imagine a different style of collaborative analysis that deviates from the typical social science “coding” formula, such as distributing interviews or field notes to a business team and asking them to record their impressions and reactions to the material using Word comments, then extracting and analyzing those to create a kind of integrated, cross-team “auto-ethnographic” register of reactions/responses. I imagine one could also come up with other inventive use cases for this tool. If you think of one, perhaps you could post it in the comments below.
Finally, since it’s so cheap to implement and simple to change or enhance, it might be usable for teaching basic coding skills (dual meaning intentional) at undergrad or graduate level.
To-Dos:
There are a few unresolved or untested issues with this macro. They are:
- Does not currently work on Microsoft Office for the Mac.
- In theory, you should be able to open multiple Word files at the same time, but this doesn’t work at present. Need to look into why.
- I would like to find a way to make this a little more “deployable,” giving users the ability to have this available as a button or default option instead of having to paste the code into the VBA Editor window every time. I tried via the ‘PERSONAL.XLSB’ route—Microsoft’s hidden spreadsheet where users can save macros for re-use—but have been unsuccessful so far.
If anyone with more VBA experience wants to offer some help, please get in touch!
Many thanks for sharing this; am doing a research project, which involves some interviews, as part of my finals. Am under time pressure and this has helped a lot!
That’s great! Happy to hear it. Good luck for your project.
thx mate
Thank you for this very thorough information. I would have loved to use it as you explicitly stated the directions. However the macro didn’t work for me. I’m not sure if it is because I’m using office 365. please advise. Thank you
Hi there. Thanks for your note. I’m sorry it’s not working for you. I have since created a new version of the script that should work on all or most platforms, including Macs and newer versions of Microsoft Office.
Please refer to this link: https://carstenknoch.com/2020/02/qualitative-data-analysis-with-microsoft-word-comments-python-updated/
I’ve updated this older post to reflect the change.
Cheap and cheerful. And super useful! Thanks :)
Hi, I have made a WordCommentsAnalyzer piece of software which basically does what is described in this macro but with some more features and more ease of use. It’s an opensource project on github:https://github.com/ehsabd/word-comments-analyzer. Also this article describes how to use it: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6137411/. Those who want to do QDA with commenting Word documents will surely find my software helpful.
Dear Carsten,
This has been very helpful guidance in my Undergraduate dissertation. I agree – I think all social science courses who teach coding should use this method. I hope Microsoft picks this up and perhaps implements a ‘button’ for it in Word!
– Philip
Terrific! I’m happy to hear that it was useful.
Thank you for sharing useful information
You have shared useful information, thank you